



ЧТО ДЕЛАТЬ С ИСКУССТВЕННЫМ ИНТЕЛЛЕКТОМ?
Елена Ларина, Владимир Овчинский
Дискуссии и решения: от экономики до войны
Стремительное развитие искусственного интеллекта, особенно разработанного на его основе чат – бота ChatGPT, вызвало во всем мире ожесточенные дискуссии о правовом регулировании ИИ, объемах выделяемых средств и его эффективности.
1. Споры в Конгрессе США
В статье Люка Хогга (директор по связям с общественностью в Фонде американских инноваций) в The National Interest “Америка не может позволить себе быть похожей на Европу в регулировании искусственного интеллекта” (22.06.2023) делается вывод о том, что“строгие правила в отношении новых приложений для систем ИИ, введенные независимо от конкретного и доказуемого вреда, скорее всего, задушат коммерческие инновации”.
В ноябре 2022 года исследовательская некоммерческая организация OpenAI выпустила в мир ChatGPT, своего чат-бота на основе искусственного интеллекта (ИИ). Всего за несколько месяцев до этого разговоры об ИИ сводились к академическим конференциям и съездам научной фантастики. Но по мере того, как ChatGPT стремительно развивался и стал самым быстрорастущим потребительским приложением в истории, искусственный интеллект быстро превратился в проблему кухонного стола. Теперь политики обращают внимание на отрасль и задают вопрос: насколько необходимо регулирование, чтобы снизить потенциальные риски, не подавляя инновации?
От правительственных отчетов до брифингов и слушаний до законодательства, искусственный интеллект является темой дня на Капитолийском холме, поскольку законодатели пытаются ответить на этот вопрос. Хотя законодательные предложения, касающиеся ИИ, сильно различаются, дух таких предложений обычно можно разделить на две категории.
Первый состоит из предложений, направленных в первую очередь на снижение потенциальных рисков ИИ, которые обычно используют более жесткий подход к регулированию во имя защиты прав потребителей.
Второй использует более широкий взгляд на экосистему ИИ, пытаясь способствовать инновациям и глобальной конкурентоспособности с помощью более мягкого режима регулирования.
“Хотя оба подхода имеют благие намерения, последний, ориентированный на инновации и конкурентоспособность, обещает больше. В конце концов, Соединенные Штаты — не единственная страна, разрабатывающая системы искусственного интеллекта, и в условиях Великого технологического соперничества важно, чтобы мы оставались конкурентоспособными в мире в области передовых технологий. Если Вашингтон будет слишком жестко регулировать ИИ, он рискует превратиться в инновационную пустыню, как и Европа”.
Тяжелая рука…
Типичным примером жесткого подхода является представитель Тед Лью (штат Калифорния). Как один из очень немногих членов Конгресса, имеющих ученые степени в области компьютерных наук, член палаты представителей Лью был одним из самых громких законодателей по вопросу регулирования ИИ. Незадолго до представления первого федерального законодательного акта, в значительной степени написанного ИИ, член палаты представителей Лью написал в New York Times:
“Стремительный прогресс в области технологий искусственного интеллекта ясно дал понять, что сейчас настало время действовать, чтобы обеспечить безопасное, этичное и полезное для общества использование ИИ. Невыполнение этого требования может привести к будущему, в котором риски ИИ намного перевешивают его преимущества…. Нам нужно специальное агентство для регулирования ИИ”.
Хотя член палаты представителей Лью признает, что у его предложения мало шансов пройти через Конгресс на этой сессии, и признает, что первым шагом на пути к регулятору ИИ является подход «изучение и отчет», Лью и многие его коллеги слишком сосредоточены на том, чтобы не дать потребителям вред, который в значительной степени остается теоретическим. Такой подход направлен на создание режима регулирования, основанного на том, что эти технологии «могут» или «могут» сделать в будущем.
Эта перспективная структура противоречит быстрым инновациям. За доказательствами нам достаточно взглянуть на Европу.
Брюссель имеет давнюю традицию жесткого регулирования технологий во имя снижения рисков для потребителей. Возьмем, к примеру, всеобъемлющую систему защиты данных Европейского Союза.
Общий регламент по защите данных (GDPR) преследует три основные цели:
защита потребителей в отношении обработки персональных данных;
защита права на защиту персональных данных;
обеспечение свободного перемещения персональных данных в пределах Союза.
В разной степени GDPR, возможно, преуспел в достижении первых двух из этих целей. Законодательство создало надежную защиту прав потребителей в отношении сбора и обработки персональных данных.
Однако в большинстве случаев GDPR не смог достичь цели обеспечения свободного перемещения данных. В первую очередь это связано с тем, что данные, беспрепятственно перемещающиеся через физические границы, не так легко препятствовать. Техническим платформам и приложениям было трудно соответствовать GDPR, что, в свою очередь, ограничивало добровольный свободный поток личной информации, а не обеспечивало его.
Согласно одному исследованию, в ходе которого было изучено более 4 миллионов программных приложений, внедрение GDPR «вызвало выход примерно трети доступных приложений». Возможно, что еще хуже, GDPR привел к нехватке технологических инноваций по всей Европе. Это же исследование показало, что выход на рынок новых приложений после введения GDPR сократился вдвое.
В настоящее время Европейский парламент разрабатывает закон, который должен стать «первым в мире всеобъемлющим законом об искусственном интеллекте». Хотя этот предлагаемый закон ЕС об искусственном интеллекте не является универсальной политикой, подобной GDPR и другим европейским техническим регламентам, он установит строгие правила для любой системы, использующей технологию искусственного интеллекта. Такие строгие правила в отношении новых приложений для систем ИИ, введенные независимо от конкретного и доказуемого вреда, скорее всего, задушат небольшие коммерческие инновации в области ИИ, которые остаются в Европе.
…по сравнению с легким прикосновением
“Соединенные Штаты не могут позволить себе идти по стопам Европы и вводить деспотичные правила, которые могут препятствовать инновациям, ради уменьшения недоказанного вреда, — пишет автор, — поскольку Китай лидирует как в инновациях, так и в регулировании ИИ , мы должны проявлять осмотрительность в нашем собственном подходе к обоим”.
“Системы ИИ, безусловно, представляют новые и уникальные риски практически во всех аспектах человеческой жизни. Но эти новые технологии также открывают новые и уникальные возможности, которым не должен препятствовать деспотический подход, вызванный моральной паникой”.
Как недавно написали эксперты в журнале American Affairs, для правильного регулирования ИИ «требуется подход, основанный на здравом смысле, который может объяснить как умопомрачительную динамику передовых систем ИИ, а также правильно оценить риски, связанные с регулированием ИИ и неправильной работой ИИ».
В то время как член палаты представителей Тед Лью и его коллеги из лагеря «небо падает» заходят слишком далеко в направлении обременительного европейского технологического регулирования, есть другой лагерь, который признает важность легкого подхода к поддержке внутренних инноваций и глобальных конкурентоспособность.
Ярким примером этого является недавно представленный закон сенаторов Майкла Беннета (штат Колумбия), Марка Уорнера (штат Вирджиния) и Тодда Янга (республиканец). В соответствии с Законом об американском технологическом лидерстве, принятым на последнем Конгрессе, это пересмотренное предложение предусматривает создание нового Управления анализа глобальной конкуренции. Целью этого нового офиса будет оценка глобальной конкурентоспособности Америки в области стратегических технологий и предоставление политических рекомендаций по способам защиты и повышения конкурентоспособности. Как заявил сенатор Беннет, цель закона состоит в том, чтобы «утратить наше конкурентное преимущество в таких стратегических технологиях, как полупроводники, квантовые вычисления и искусственный интеллект, таким конкурентам, как Китай».
Этот второй лагерь, представленный сенатором Беннетом и его коллегами, менее реактивен, более конструктивен, учитывает важность глобальной конкуренции и признает, что необходима осторожность, чтобы избежать навязывания жестких правил, которые препятствуют инновациям и ограничивают способность страны идти в ногу с достижениями ИИ. Чтобы было ясно, эти законодатели не игнорируют реальные риски, связанные с системами ИИ. Скорее, они рассматривают такие риски в глобальной перспективе и делают более обоснованные расчеты относительно надлежащего уровня регулирования.
Поддержание американских инноваций
“Создавая среду, поощряющую как внутреннюю, так и глобальную конкуренцию в области технологий ИИ, и создавая нормативно-правовую базу, способствующую ответственному использованию ИИ, Соединенные Штаты могут сохранить свое мировое лидерство в этой важнейшей области”, считает Люг Хогг. “Принимая легкое регулирование, ориентированное на глобальную конкурентоспособность, политики могут поощрять инвестиции, привлекать лучших специалистов в области ИИ и создавать среду, которая позволяет американским компаниям лидировать в разработке ИИ. Предоставляя пространство для экспериментов и адаптации, Соединенные Штаты могут оставаться в авангарде инноваций в области искусственного интеллекта, обеспечивая экономические и социальные преимущества, сохраняя при этом конкурентное преимущество на мировой арене”.
2. Большие языковые модели ИИ: объемы и затраты
Журнал The Economist опубликовал статью «Подход «чем больше, тем лучше» к ИИ иссякает” (21.06.2023), которой делается вывод, что“если ИИ хочет продолжать совершенствоваться, ему придется делать больше с меньшими затратами”.
GPT — 3, выпущенный в 2020 году, был гигантом. У него было 175 миллиардов «параметров», как называются смоделированные связи между этими нейронами. Он был обучен на тысячах графических процессоров (специализированных чипов, которые преуспевают в области искусственного интеллекта). Он перемалывать сотни миллиардов слов текста в течение нескольких недель. Все это обошлось не менее чем в 4,6 миллиона долларов.
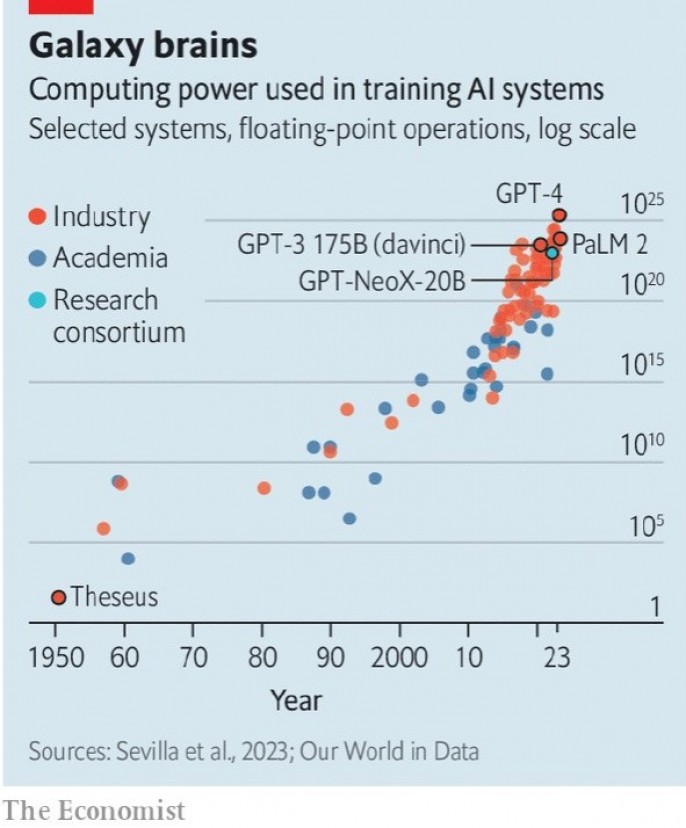
Модели растут стремительными темпами. Считается, что GPT — 4, выпущенный в марте 2023 года, имеет около 1 триллиона параметров — почти в шесть раз больше, чем его предшественник. Сэм Альтман, глава фирмы, оценил затраты на разработку более чем в 100 миллионов долларов. Подобные тенденции существуют во всей отрасли. Исследовательская фирма Epoch AI подсчитала, что в 2022 году вычислительная мощность, необходимая для обучения передовой модели, удваивалась каждые шесть — десять месяцев (см. диаграмму).
Этот гигантизм становится проблемой. Если цифра удвоения Epoch AI за десять месяцев верна, то к 2026 году затраты на обучение могут превысить миллиард долларов — при условии, что у моделей не закончатся данные первыми. Анализ, опубликованный в октябре 2022 года, прогнозирует, что запас качественного текста для обучения вполне может быть исчерпан примерно в то же время. И даже после завершения обучения фактическое использование полученной модели также может быть дорогостоящим.
Чем больше модель, тем дороже она стоит. Ранее в этом году банк Morgan Stanley предположил, что если половина поисковых запросов Google будет обрабатываться текущей программой в стиле GPT, это может обойтись фирме в дополнительные 6 миллиардов долларов в год.
По мере того, как модели становятся больше, это число, вероятно, будет расти.
Поэтому многие в этой области считают, что подход «чем больше, тем лучше» исчерпал себя. Если модели ии будут продолжать совершенствоваться — не говоря уже о том, чтобы воплотить в жизнь мечты об ИИ , охватившие в настоящее время всю технологическую отрасль, — их создателям нужно будет придумать, как добиться большей производительности при меньшем количестве ресурсов. Как сказал г-н Альтман в апреле, размышляя об истории гигантского ии : «Я думаю, что мы находимся в конце эпохи».
Количественное затягивание
Вместо этого исследователи начинают обращать внимание на то, чтобы сделать свои модели более эффективными, а не просто большими.
Один из подходов состоит в том, чтобы пойти на компромисс, сократив количество параметров, но обучая модели с использованием большего количества данных. В 2022 году исследователи из DeepMind, подразделения Google, обучили Chinchilla, llm с 70 миллиардами параметров, корпусу из 1,4 триллиона слов. Модель превосходит GPT — 3, которая имеет 175 миллиардов параметров, обученных на 300 миллиардах слов. Подача меньшего llm большего количества данных означает, что обучение занимает больше времени. Но в результате получается модель меньшего размера, которая быстрее и дешевле в использовании.
Другой вариант — сделать математику более размытой. Отслеживание меньшего количества знаков после запятой для каждого числа в модели — другими словами, их округление — может значительно сократить требования к оборудованию. В марте 2023 года исследователи из Института науки и технологий в Австрии показали, что округление может сократить объем памяти, потребляемой моделью, подобной GPT — 3, что позволяет модели работать на одном высокопроизводительном графическом процессоре вместо пяти и только с «незначительное снижение точности».
Некоторые пользователи настраивают на llm общего назначения , чтобы сосредоточиться на конкретной задаче, такой как создание юридических документов или обнаружение фальшивых новостей.
Исследователи из Вашингтонского университета изобрели более эффективный метод, который позволил им создать новую модель Guanaco на одном графическом процессоре за день без существенного ущерба для производительности. Частично хитрость заключалась в том, чтобы использовать ту же технику округления, что и австрийцы. Но они также использовали технику под названием «адаптация низкого ранга», которая включает в себя замораживание существующих параметров модели, а затем добавление нового, меньшего набора параметров между ними. Тонкая настройка выполняется путем изменения только этих новых переменных. Это настолько упрощает задачу, что даже относительно слабые компьютеры, такие как смартфоны, могут справиться с этой задачей. Разрешение llm жить на устройстве пользователя, а не в гигантских центрах обработки данных, в которых он сейчас обитает, может обеспечить как большую персонализацию, так и большую конфиденциальность.
Тем временем команда Google предложила другой вариант для тех, кто может обойтись меньшими моделями. Этот подход фокусируется на извлечении конкретных знаний, необходимых из большой модели общего назначения, в меньшую специализированную модель. Большая модель выступает в роли учителя, а меньшая — в роли ученика. Исследователи просят преподавателя ответить на вопросы и показать, как он приходит к своим выводам. И ответы, и рассуждения учителя используются для обучения модели ученика. Команда смогла обучить модель ученика всего с 770 миллионами параметров, что превзошло ее учителя с 540 миллиардами параметров в специализированной задаче на рассуждения.
Вместо того, чтобы сосредоточиться на том, что делают модели, можно изменить способ их создания. Большая часть программирования ии выполняется на языке под названием Python. Он разработан, чтобы быть простым в использовании, освобождая программистов от необходимости думать о том, как именно их программы будут вести себя на чипах, которые их запускают. Цена абстрагирования таких деталей — медленный код. Уделение большего внимания этим деталям реализации может принести большую пользу.
Научитесь программировать
В 2022 году исследователи из Стэнфордского университета опубликовали модифицированную версию «алгоритма внимания», который позволяет llm изучать связи между словами и идеями. Идея состояла в том, чтобы изменить код, чтобы он учитывал то, что происходит на чипе, на котором он работает, и особенно для отслеживания того, когда данный фрагмент информации необходимо искать или сохранять. Их алгоритм смог ускорить обучение GPT -2, более старой большой языковой модели, в три раза. Это также дало ему возможность отвечать на более длинные запросы.
Более изящный код также может быть получен с помощью более качественных инструментов. Ранее в этом году Meta выпустила обновленную версию PyTorch, фреймворка для программирования искусственного интеллекта . Позволяя программистам больше думать о том, как вычисления организованы на реальном чипе, он может удвоить скорость обучения модели, добавив всего одну строку кода.
Modular, стартап, основанный бывшими инженерами Apple и Google, в прошлом месяце выпустил новый язык программирования, ориентированный на ии , под названием Mojo, основанный на Python. Это также дает программистам контроль над всевозможными мелкими деталями, которые ранее были скрыты. В некоторых случаях код, написанный на Mojo, может работать в тысячи раз быстрее, чем тот же код на Python.
Большинство экспертов считают, что есть еще много возможностей для улучшения. Как сказал Крис Мэннинг, ученый-компьютерщик из Стэнфордского университета: «Нет абсолютно никаких оснований полагать… что это идеальная нейронная архитектура, и мы никогда не найдем ничего лучше».
3. Путь к GPT-5
Тушар Мехта в статье на сайте Slash Gear “Вот все, что мы знаем о большой языковой модели OpenAI GPT-5. Когда выйдет GPT-5?” (25.06.2023) пишет:
“OpenAI выпустилаGPT-3 в июне 2020 года, а в марте 2022 года последовала более новая версия, называемая внутри компании «davinci-002». ChatGPT в ноябре 2022 года, а затем выпуск GPT-4 в марте 2023 года.
Судя по траектории предыдущих выпусков, OpenAI может не выпускать GPT-5 в течение нескольких месяцев. Это может быть отложено из-за общего чувства паники, которое создали инструменты искусственного интеллекта, такие как ChatGPT, во всем мире.
GPT-4 вызвал многочисленные споры об этичности использования ИИ и о том, как он может нанести ущерб человечеству. Вскоре за ним последовало открытое письмо, подписанное сотнями технических лидеров, педагогов и высокопоставленных лиц, включая Илона Маска и Стива Возняка, с призывом приостановить обучение систем, «более продвинутых, чем GPT-4».
С тех пор генеральный директор OpenAI Сэм Альтман как минимум дважды заявлял, что OpenAI не работает над GPT-5. В июне 2023 года на пресс-конференции, организованной The Economic Times в Нью-Дели, Индия, Альтман сказал: «Нам предстоит проделать большую работу до GPT5. Это требует много времени. Мы и не близки к этому». Ранее, в апреле 2023 года, Альтман выступил на мероприятии Массачусетского технологического института и подтвердил, что OpenAI «некоторое время не будет работать на GPT-5». Исполнительный директор добавил: «Помимо GPT-4 мы делаем и другие вещи, которые, как мне кажется, связаны со всевозможными проблемами безопасности, которые важно решить».
Основные ожидания от GPT-5: больше мощности, лучшая цена.
GPT-4 в настоящее время способен обрабатывать запросы только с 8 192 токенами, что приблизительно соответствует 6 144 словам. OpenAI на короткое время позволил первоначальным тестировщикам запускать команды с использованием до 32 768 токенов (примерно 25 000 слов или 50 страниц контекста), и это будет широко доступно в следующих выпусках. Текущая длина запросов GPT-4 в два раза больше, чем поддерживается в бесплатной версии GPT-3.5, и мы можем ожидать поддержки гораздо больших входных данных с GPT-5.
Примечательно, что эти более крупные запросы также имеют свою цену. В то время как GPT-3.5 можно использовать бесплатно через ChatGPT, GPT-4 доступен только пользователям платного уровня под названием ChatGPT Plus. Цены начинаются от 20 долларов в месяц, что может быть сдерживающим фактором. С GPT-5, по мере увеличения вычислительных требований и повышения квалификации чат-бота, мы также можем увидеть рост цен. На данный момент вы можете вместо этого использовать чат Microsoft Bing AI Chat, который также основан на GPT-4 и может использоваться бесплатно. Однако вы будете привязаны к браузеру Microsoft Edge, где чат-бот с искусственным интеллектом будет следовать за вами повсюду в вашем путешествии по сети в качестве «второго пилота».
Фактическая правильность и меньше галлюцинаций
Ожидается, что помимо того, что GPT-5 лучше выдает более быстрые результаты, он будет более точным с точки зрения фактов. В последние месяцы мы стали свидетелями нескольких случаев, когда ChatGPT, Bing AI Chat или Google Bard извергали абсолютную чепуху, иначе называемую «галлюцинациями» в технических терминах. Это связано с тем, что эти модели обучаются на ограниченных и устаревших наборах данных. Например, бесплатная версия ChatGPT, основанная на GPT-3.5, содержит информацию только до июня 2021 года и может неточно отвечать на вопросы о событиях после этого.
Для сравнения, GPT-4 был обучен на более широком наборе данных, который по-прежнему относится к сентябрю 2021 года. OpenAI отметил тонкие различия между GPT-4 и GPT-3.5 в обычных разговорах. GPT-4 также показал себя более опытным во множестве тестов, включая Unform Bar Exam, LSAT, AP Calculus и т. д. Кроме того, он превзошел тесты машинного обучения GPT-3.5 не только на английском, но и на 23 других языках.
OpenAI заявила, что GPT-4 имеет гораздо меньше галлюцинаций и работает на 40% выше, чем GPT-3.5 в своих «внутренних состязательных оценках достоверности». Более того, GPT-4 на 82% реже отвечает на «чувствительные запросы» или «запрещенный контент», такие как членовредительство или медицинские запросы. Несмотря на это, GPT-4 демонстрирует различные предубеждения, но OpenAI заявляет, что совершенствует существующие системы, чтобы отражать общечеловеческие ценности и учиться на человеческом вкладе и отзывах.
Устранение неверных ответов от GPT-5 станет ключом к его более широкому внедрению в будущем, особенно в таких важных областях, как медицина и образование.
Мультимодальные возможности
GPT-4 не знает о реальных событиях после сентября 2021 года, но недавно был обновлен с возможностью подключения к Интернету в бета-версии с помощью специального плагина для просмотра веб-страниц. Чат Microsoft Bing AI, построенный на GPT OpenAI и недавно обновленный до GPT-4, уже позволяет пользователям получать результаты из Интернета. Хотя это означает доступ к более актуальным данным, вы обязаны получать результаты с ненадежных веб-сайтов, которые занимают высокие позиции в результатах поиска с незаконными методами SEO. Еще неизвестно, как эти модели ИИ противодействуют этому и дают только надежные результаты, а также работают быстро. Это может быть одной из областей, которые нужно улучшить в будущих моделях OpenAI, особенно GPT-5.
Помимо веб-поиска, GPT-4 также может использовать изображения в качестве входных данных для лучшего контекста. Это, однако, в настоящее время ограничено предварительным просмотром исследования и будет доступно в последовательных обновлениях модели. Можно ожидать, что будущие версии, особенно GPT-5, получат более широкие возможности для обработки данных в различных формах, таких как аудио, видео и т. д.
Meta недавно опубликовала подробности о своей мультимодальной модели искусственного интеллекта ImageBind, которая может обрабатывать шесть различных типов данных: текст, изображения, видео, аудио, глубину и тепловые карты. Можно легко ожидать, что OpenAI также продвинется в этой области к тому времени, когда он выпустит GPT-5, сделав его более полезным в различных областях работы и не ограничивая его работой только в качестве чат-бота или генератора изображений AI.
Ожидания и опасения по поводу общего искусственного интеллекта
Основным недостатком современных больших языковых моделей является то, что их необходимо обучать на данных, вводимых вручную. Естественно, один из самых больших переломных моментов в искусственном интеллекте наступит, когда ИИ сможет воспринимать информацию и учиться, как люди. Это состояние автономного обучения, подобного человеческому, называется общим искусственным интеллектом или ОИИ. Согласно IBM, ОИИ — это этап, когда машины «будут иметь самосознающее сознание, способное решать проблемы, учиться и планировать будущее». ОИИ по-прежнему является теоретической концепцией, и исследователи и заинтересованные стороны ИИ расходятся во мнениях относительно точного времени его появления. Но недавний бум популярности ChatGPT привел к предположениям, связывающим GPT-5 с AGI.
Такие инструменты, как Auto-GPT, позволяют нам заглянуть в будущее, когда AGI реализуется. Auto-GPT — это инструмент с открытым исходным кодом, первоначально выпущенный на GPT-3.5, а затем обновленный до GPT-4, способный выполнять задачи автоматически с минимальным участием человека.
Учитывая то, как он делает машины способными принимать собственные решения, ОИИ рассматривается как угроза человечеству, что отражено в блоге, написанном Сэмом Альтманом в феврале 2023 года. В блоге Альтман взвешивает потенциальные преимущества ОИИ, ссылаясь на риск «тяжких к миру.» Генеральный директор OpenAI также призывает к глобальным соглашениям об управлении, распределении преимуществ и совместном доступе к ИИ.
Хотя ожидать, что GPT-5 создаст ОИИ, может быть преувеличением, особенно в ближайшие несколько лет, полностью исключать такую возможность нельзя.
4. ИИ и экономика
Дамбасо Мойо в статье в Project Syndicate “Экономическая модель для эпохи ИИ” (22.06.2023) пишет:
“Поскольку искусственный интеллект снижает спрос на рабочую силу и повышает производительность, правительствам и предприятиям придется приспосабливаться. Хотя правительства могут захотеть повысить налоги и перераспределить доходы, чтобы смягчить краткосрочные сбои, в долгосрочной перспективе им нужно будет мыслить шире”.
В апреле 2023 года генеральный директор Alphabet Сундар Пичаи предсказал, что “искусственный интеллект окажет «более глубокое» влияние, чем любые другие человеческие инновации, от огня до электричества”. Хотя невозможно точно знать, каким будет это влияние, два изменения кажутся особенно вероятными: спрос на рабочую силу упадет, а производительность возрастет. Другими словами, мы, похоже, движемся к экономической модели без труда, в которой для поддержания роста требуется меньше людей.
Работа в сфере поддержки бэк-офиса, юридических услуг и бухгалтерского учета, кажется, сталкивается с самым непосредственным риском из-за новых генеративных технологий искусственного интеллекта, включая большие языковые модели, такие как ChatGPT-4. Но, скорее всего, пострадает каждый сектор экономики. Поскольку языковые задачи занимают 62% рабочего времени сотрудников, согласно недавнему отчету Accenture, большие языковые модели могут занимать 40% всего рабочего времени.
По оценкам Accenture, 65% времени, затрачиваемого на эти языковые задачи, можно «превратить в более продуктивную деятельность за счет дополнений и автоматизации». А в новом отчете McKinsey прогнозируется, что повышение производительности за счет ИИ может ежегодно увеличивать стоимость мировой экономики на сумму, эквивалентную 2,6–4,4 трлн долларов.
Но даже если более высокая производительность способствует экономическому росту, сокращение рабочей силы подорвет его, а это означает, что в конечном итоге рост вполне может застопориться. Сокращение спроса на рабочую силу означает резкий рост безработицы, особенно с учетом того, что население мира будет продолжать расти.
Безработица уже является постоянной проблемой. По данным Международной организации труда, общее число безработных молодых людей (15-24 лет) уже более двух десятилетий составляет около 70 миллионов человек. А глобальный уровень безработицы среди молодежи имеет тенденцию к росту: с 12,2% в 1995 году до чуть менее 13% после мирового финансового кризиса 2008 года и до 15,6% в 2021 году.
ИИ усугубит эти тенденции. А поскольку влияние ИИ на рынки труда, скорее всего, будет структурным, рост безработицы приведет к постоянному перемещению. Структурная безработица может вернуться к уровням, которые в последний раз наблюдались во время деиндустриализации 1980-х годов, когда безработица в Соединенном Королевстве, например, оставалась выше 10% на протяжении большей части 1980-х годов.
Как правительства могут поддержать рост ВВП в новую эру устойчивой структурной безработицы? Наиболее очевидным вероятным ответом является переход к большему перераспределению, при котором правительства повышают налоги на доходы от повышения производительности за счет ИИ и используют эти доходы для поддержки более широких слоев населения, в том числе путем внедрения той или иной версии всеобщего базового дохода.
Чтобы обеспечить достаточный доход для поддержки расширенных сетей социальной защиты, правительства могут перейти от налогообложения избыточной прибыли, полученной в результате повышения производительности за счет ИИ, к налогообложению доходов фирм, получающих самые большие выгоды. Таким образом, государство — и, в свою очередь, население в целом — получат большую долю непредвиденных доходов от ИИ.
Конечно, революция ИИ также имеет серьезные последствия для бизнеса. Для начала компаниям придется скорректировать свои стратегии и операции с учетом сочетания более высокой производительности и меньшей рабочей силы, что позволит им производить больше продукции с меньшим капиталом. Компании, которые приспосабливаются по мере необходимости и обеспечивают низкое соотношение затрат к доходам, будут привлекать инвесторов. Те, кто медленно меняет свои операционные модели, потеряют конкурентоспособность и могут потерпеть неудачу.
Последствия таких корпоративных корректировок отразятся на всей экономике. Сокращение спроса на капитал со стороны фирм будет оказывать понижательное давление на стоимость капитала, и компании будут меньше нуждаться в заимствованиях в банках, что также приведет к снижению общей активности на рынках капитала.
Более высокие налоги на корпоративную прибыль (или доходы) создадут дополнительные проблемы. Хотя государству потребуется увеличить доходы для поддержки растущего числа безработных, это может привести к тому, что корпорации с более низкой нераспределенной прибылью будут реинвестировать, несмотря на дополнительную прибыль, полученную за счет повышения производительности за счет ИИ.
Это плохо не только для самих компаний. Меньшие инвестиции в экономику подорвут экономический рост, сократят экономический пирог и снизят уровень жизни. Это также сузит налоговую базу, подорвет средний класс и усилит неравенство между владельцами капитала и традиционной рабочей силой.
Таким образом, хотя правительства могут захотеть повысить налоги и перераспределить доходы, чтобы смягчить краткосрочные сбои, вызванные ИИ, в долгосрочной перспективе им нужно будет мыслить шире. Фактически, политикам придется переосмыслить преобладающие экономические модели и принципы, начиная с предположения, что труд является ключевым двигателем роста. В эпоху ИИ работники могут мало что делать для стимулирования роста, но они должны извлекать из этого пользу”.
5. Пентагон и искусственный интеллект
15 июня 2023 года заместитель министра обороны Кэтлин Хикс опубликовала статью в POLITICO «Что Пентагон думает об искусственном интеллекте», проливая свет на точку зрения Пентагона на потенциальные риски использования искусственного интеллекта, особенно великими державами:
“Искусственный интеллект может трансформировать многие аспекты жизни человека, особенно в военной сфере. Хотя многие американцы, возможно, только сейчас обратили внимание на потенциальные перспективы и опасности ИИ, Министерство обороны США уже более десяти лет работает над обеспечением его ответственного использования. Теперь задача состоит в том, чтобы убедить другие страны, в том числе Китайскую Народную Республику, присоединиться к Соединенным Штатам в соблюдении норм ответственного поведения ИИ.
Пентагон впервые опубликовал политику ответственного использования автономных систем и ИИ в 2012 году. С тех пор мы придерживаемся своих обязательств, даже несмотря на развитие технологий. В последние годы мы приняли этические принципы использования ИИ и выпустили ответственную стратегию и путь внедрения ИИ. В 2023 году мы также обновили нашу первоначальную директиву 2012 года об автономности систем вооружения, чтобы гарантировать, что мы остаемся мировым лидером не только в области разработки и развертывания, но и в области безопасности.
Там, где министерство обороны инвестирует в ИИ, мы делаем это в областях, которые дают нам наибольшую стратегическую выгоду и извлекают выгоду из наших существующих преимуществ. Мы также проводим четкую линию, когда речь идет о ядерном оружии. Политика Соединенных Штатов заключается в том, чтобы держать человека «в курсе» всех действий, имеющих решающее значение для информирования и исполнения решений президента о начале и прекращении применения ядерного оружия.
Хотя мы быстро внедряем ИИ во многие другие аспекты нашей миссии — от осведомленности о боевом пространстве, кибербезопасности и разведки до логистики, поддержки сил и других вспомогательных функций — мы помня о потенциальных опасностях ИИ, которых мы полны решимости их избегать.
Мы не используем ИИ для цензуры, ограничения, подавления или лишения прав людей. Ставя наши ценности на первое место и используя наши сильные стороны, величайшей из которых являются наши люди, мы придерживаемся ответственного подхода к ИИ, который гарантирует, что Америка продолжит выходить вперед.
Наш текущий уровень финансирования ИИ отражает наши нынешние потребности: оборонный бюджет США на 2024 финансовый год предусматривает инвестиции в размере 1,8 миллиарда долларов в искусственный интеллект и возможности машинного обучения, чтобы продолжить наш прогресс в области модернизации и инноваций. Это изменится со временем, когда мы эффективно внедрим технологии в нашу работу, оставаясь при этом верными принципам, которые делают нашу боевую силу лучшей в мире.
Несмотря на то, что наше использование ИИ отражает нашу этику и наши демократические ценности, мы не стремимся контролировать инновации. Динамичная инновационная экосистема Америки не имеет себе равных, потому что она основана на свободном и открытом обществе творческих изобретателей, деятелей и решателей проблем. Хотя это заставляет меня выбирать нашу систему свободного рынка государственной системе Китая в любой день недели, это не означает, что эти две системы не могут сосуществовать.
Согласно новостным сообщениям, китайские дипломаты заявили , что КНР «очень серьезно относится к необходимости предотвращения и управления рисками и проблемами, связанными с ИИ». Это хорошие слова; действия важнее. Если Китай действительно «готов активизировать обмены и сотрудничество со всеми сторонами», Пентагон будет приветствовать такое прямое взаимодействие.
Наша приверженность ценностям — одна из причин, по которой у Соединенных Штатов и их вооруженных сил так много способных союзников и партнеров по всему миру, а также растущее число новаторов в области коммерческих технологий, которые хотят работать с нами: потому что они разделяют наши ценности.
Такие ценности не принадлежат ни стране, ни компании. Другие страны могут принять их. Например, если КНР надежно и поддающимся проверке образом привержена сохранению участия человека во всех действиях, имеющих решающее значение для информирования и исполнения суверенных решений об использовании ядерного оружия, она может обнаружить, что это обязательство тепло воспринято ее соседями и другими членами международного сообщества. И это правильно.
Соединенные Штаты не стремятся к гонке вооружений ИИ или любой гонке вооружений с Китаем, как и мы не стремимся к конфликту. С помощью ИИ и всех наших возможностей мы стремимся только сдерживать агрессию и защищать нашу страну, наших союзников и партнеров и наши интересы.
Америка и Китай соревнуются в формировании будущего 21-го века в технологическом и ином плане. Это соревнование мы намерены выиграть — не вопреки нашим ценностям, а благодаря им”.
Приложение 1
Политическая декларация об ответственном военном использовании искусственного интеллекта и автономии:
Все большее число государств разрабатывают военные возможности искусственного интеллекта, которые могут включать использование искусственного интеллекта для включения автономных систем. Использование ИИ в военных целях может и должно быть этичным, ответственным и укреплять международную безопасность. Использование ИИ в вооруженном конфликте должно соответствовать применимому международному гуманитарному праву, включая его основополагающие принципы. Военное использование возможностей ИИ должно быть подотчетным, в том числе посредством такого использования во время военных операций в рамках ответственной цепочки командования и управления людьми. Принципиальный подход к использованию ИИ в военных целях должен включать тщательное рассмотрение рисков и выгод, а также сводить к минимуму непреднамеренную предвзятость и несчастные случаи. Государствам следует принять соответствующие меры для обеспечения ответственной разработки, развертывания и использования своих военных возможностей искусственного интеллекта, в том числе тех, которые позволяют использовать автономные системы. Эти меры следует применять на протяжении всего жизненного цикла возможностей военного ИИ.
Следующие утверждения отражают передовой опыт, который, по мнению одобряющих государств, должен быть реализован при разработке, развертывании и использовании возможностей военного ИИ, в том числе тех, которые позволяют использовать автономные системы:
Государствам следует предпринимать эффективные шаги, такие как юридические проверки, чтобы гарантировать, что их военные возможности искусственного интеллекта будут использоваться только в соответствии с их соответствующими обязательствами по международному праву, в частности международному гуманитарному праву.
Государства должны сохранять человеческий контроль и участие во всех действиях, имеющих решающее значение для информирования и выполнения суверенных решений, касающихся применения ядерного оружия.
Государствам следует обеспечить, чтобы старшие должностные лица контролировали разработку и развертывание всех военных возможностей искусственного интеллекта с серьезными последствиями, включая, помимо
прочего, системы вооружения.
Государства должны принять, опубликовать и внедрить принципы ответственного проектирования, разработки, развертывания и использования возможностей ИИ своими военными организациями.
Государствам следует обеспечить, чтобы соответствующий персонал проявлял надлежащую осмотрительность, включая надлежащий уровень человеческого суждения, при разработке, развертывании и использовании военных возможностей искусственного интеллекта, включая системы вооружения, включающие такие возможности.
Государствам следует обеспечить принятие обдуманных мер для сведения к минимуму непреднамеренной предвзятости в возможностях военного ИИ.
Государствам следует обеспечить, чтобы военные возможности искусственного интеллекта разрабатывались с использованием поддающихся проверке методологий, источников данных, процедур проектирования и документации.
Государства должны обеспечить, чтобы персонал, который использует или одобряет использование военных возможностей искусственного интеллекта, был обучен, чтобы они в достаточной степени понимали возможности и ограничения этих возможностей и могли делать выводы об их использовании с учетом контекста.
Государствам следует обеспечить, чтобы возможности военного ИИ имели явное, четко определенное применение и чтобы они были спроектированы и спроектированы для выполнения этих предполагаемых функций.
Государствам следует обеспечить, чтобы безопасность, защищенность и эффективность военных возможностей искусственного интеллекта подвергались надлежащему и строгому тестированию и проверке в рамках их четко определенного использования и на протяжении всего их жизненного цикла. Самообучающиеся или постоянно обновляемые возможности военного ИИ также должны подвергаться процессу мониторинга, чтобы гарантировать, что критически важные функции безопасности не ухудшились.
Государствам следует проектировать и разрабатывать военные средства искусственного интеллекта, чтобы они обладали способностью обнаруживать и предотвращать непреднамеренные последствия, а также отключать или деактивировать развернутые системы, демонстрирующие непреднамеренное поведение. Государствам также следует применять другие соответствующие меры предосторожности для снижения рисков серьезных отказов. Эти меры безопасности могут быть взяты из тех, которые предназначены для всех военных систем, а также для возможностей ИИ, не предназначенных для военного использования.
Государствам следует продолжить обсуждение того, как военные возможности ИИ разрабатываются, развертываются и используются ответственным образом, чтобы способствовать эффективному внедрению этих практик и внедрению других практик, которые одобряющие государства сочтут целесообразными. Эти обсуждения должны включать рассмотрение того, как реализовать эти методы в контексте их экспорта военных возможностей искусственного интеллекта.
Поддерживающие государства будут:
внедрить эти методы при разработке, развертывании или использовании возможностей военного ИИ, в том числе тех, которые позволяют использовать автономные системы;
публично описывать свою приверженность этим практикам;
поддерживать другие соответствующие усилия для обеспечения ответственного и законного использования таких возможностей; и
и далее привлекать остальную часть международного сообщества к продвижению этой практики, в том числе на других форумах по смежным темам, и без ущерба для текущих дискуссий по смежным темам на других форумах.
Для целей настоящей Декларации под искусственным интеллектом можно понимать способность машин выполнять задачи, которые в противном случае потребовали бы человеческого интеллекта, например, распознавание закономерностей, обучение на опыте, выводы, предсказания или действия, независимо от того, в цифровом виде или как интеллектуальное программное обеспечение для автономных физических систем. Точно так же под автономией можно понимать систему, работающую без дальнейшего вмешательства человека после активации.
Приложение 2
Этические принципы искусственного интеллекта Министерства обороны США:
1. Ответственность: персонал Министерства обороны будет проявлять надлежащий уровень суждения и осторожности, оставаясь при этом ответственным за разработку, развертывание и использование возможностей ИИ.
2. Справедливость: Министерство предпримет преднамеренные шаги, чтобы свести к минимуму непреднамеренную предвзятость в возможности ИИ.
3. Отслеживаемость: возможности искусственного интеллекта Министерства будут разрабатываться и развертываться с учетом того, что соответствующий персонал обладает надлежащим пониманием технологии, разработки процессов и методов работы, применимых к возможностям ИИ. В том числе использует прозрачные и проверяемые методологии, источники данных, процедуры проектирования и документация.
4. Надежность: возможности искусственного интеллекта Министерства будут иметь явное, четко определенное использование и безопасность, защищенность и эффективность таких возможностей. Будут подлежать тестированию и гарантиям в рамках определенных видов использования на протяжении всего жизненного цикла возможностей ИИ.
5. Управляемость: Министерство будет разрабатывать и внедрять возможности ИИ для выполнения своих предназначенных функций, обладая при этом способностью обнаруживать и предотвращать непреднамеренные последствия, а также возможность отключать или деактивировать развернутые системы, которые продемонстрировали непреднамеренное поведение.
Этические принципы ИИ Министерства обороны США основываются на существующих этических, правовых принципах, а также принципах политики и безопасности, которые являются отличительной чертой Министерства. Они применяются ко всем возможностям любого масштаба, включая автономные системы с поддержкой ИИ, для ведения боевых действий и бизнес-приложений.
Чтобы ценности нашей нации были воплощены в возможностях ИИ, поскольку Министерство разрабатывает, закупает и внедряет ИИ, эти принципы будут реализованы не только в технологии, но и в операционных структурах предприятия и организационной культуре.
Материалы по теме
 КИТАЙ — США: БИТВА ИНТЕЛЛЕКТОВ
КИТАЙ — США: БИТВА ИНТЕЛЛЕКТОВ ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ И ДРУГИЕ ИННОВАЦИИ В СХВАТКЕ МЕЖДУ «ДЕМОКРАТИЕЙ» И «АВТОКРАТИЕЙ»
ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ И ДРУГИЕ ИННОВАЦИИ В СХВАТКЕ МЕЖДУ «ДЕМОКРАТИЕЙ» И «АВТОКРАТИЕЙ» США ГОТОВЯТСЯ К ВЫСОКОТЕХНОЛОГИЧЕСКОЙ ВОЙНЕ С КИТАЕМ И РОССИЕЙ
США ГОТОВЯТСЯ К ВЫСОКОТЕХНОЛОГИЧЕСКОЙ ВОЙНЕ С КИТАЕМ И РОССИЕЙ США ГОТОВЯТСЯ К ВЫСОКОТЕХНОЛОГИЧЕСКОЙ ВОЙНЕ С КИТАЕМ И РОССИЕЙ
США ГОТОВЯТСЯ К ВЫСОКОТЕХНОЛОГИЧЕСКОЙ ВОЙНЕ С КИТАЕМ И РОССИЕЙ США ГОТОВЯТСЯ К ВЫСОКОТЕХНОЛОГИЧЕСКОЙ ВОЙНЕ С КИТАЕМ И РОССИЕЙ
США ГОТОВЯТСЯ К ВЫСОКОТЕХНОЛОГИЧЕСКОЙ ВОЙНЕ С КИТАЕМ И РОССИЕЙ





